
I am a research scientist on the Health AI team at Apple, working on new machine learning and statistical methods for health applications. Before that, I was a postdoctoral research scientist at the Data Science Institute at Columbia University where I worked on methods for statistical modeling and inference with John Cunningham and Dave Blei. Before Columbia, I completed my PhD in Computer Science at Harvard University, advised by Ryan Adams, with a focus on probabilistic modeling and scalable inference methods. I like to be application-driven; my applied work ranges from problems in astronomy to health care to sports analytics. On applications in health care, I have worked with Ziad Obermeyer and Sendhil Mullainathan. On applications in sports analytics, I worked closely with Luke Bornn.
Publications
-
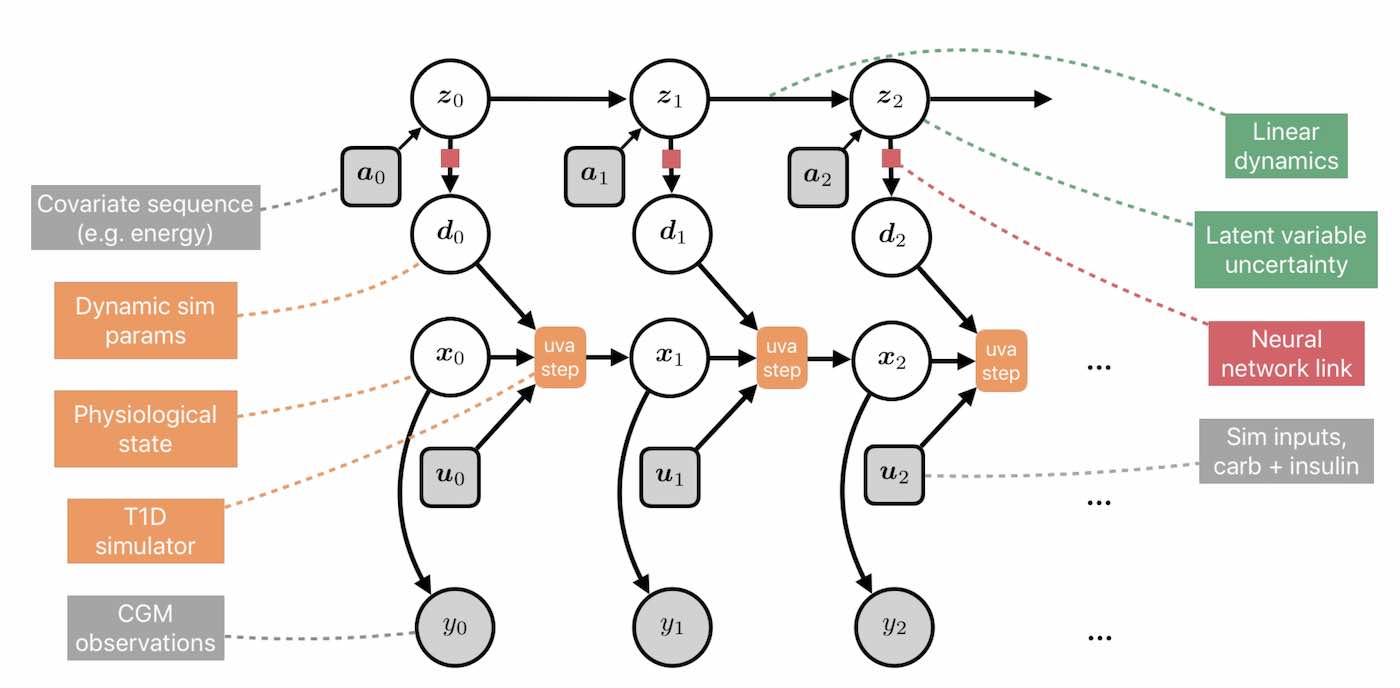
Learning Insulin-Glucose Dynamics in the Wild
Andrew C. Miller, Nicholas J. Foti, and Emily B. Fox
Machine Learning for Healthcare, 2020
[abstract] [arxiv]We develop a new model of insulin-glucose dynamics for forecasting blood glucose in type 1 diabetics. We augment an existing biomedical model by introducing time-varying dynamics driven by a machine learning sequence model. Our model maintains a physiologically plausible inductive bias and clinically interpretable parameters -- e.g., insulin sensitivity -- while inheriting the flexibility of modern pattern recognition algorithms. Critical to modeling success are the flexible, but structured representations of subject variability with a sequence model. In contrast, less constrained models like the LSTM fail to provide reliable or physiologically plausible forecasts. We conduct an extensive empirical study. We show that allowing biomedical model dynamics to vary in time improves forecasting at long time horizons, up to six hours, and produces forecasts consistent with the physiological effects of insulin and carbohydrates. -

Comment: Variational Autoencoders as Empirical Bayes
Yixin Wang, Andrew C. Miller, and David M. Blei
Statistical Science, 2019
[abstract] [link] [original article | rejoinder]In this comment, we discuss the connection between empirical Bayes and the variational autoencoder (VAE), a popular statistical inference framework in the machine learning community. We hope this connection motivates new algorithmic approaches for empirical Bayesians and gives new perspectives on VAEs for machine learners. -
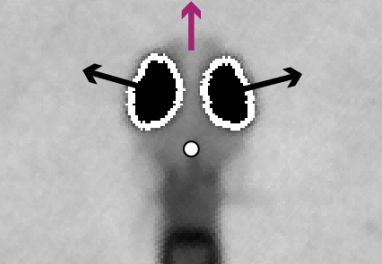
Probabilistic Models of Larval Zebrafish Behavior: Structure on Many Scales
Robert Evan Johnson, Scott Linderman, Thomas Panier, Caroline Lei Wee, Erin Song, Kristian Joseph Herrera, Andrew Miller, Florian Engert
[abstract] [bioarxiv]Nervous systems have evolved to combine environmental information with internal state to select and generate adaptive behavioral sequences. To better understand these computations and their implementation in neural circuits, natural behavior must be carefully measured and quantified. Here, we collect high spatial resolution video of single zebrafish larvae swimming in a naturalistic environment and develop models of their action selection across exploration and hunting. Zebrafish larvae swim in punctuated bouts separated by longer periods of rest called interbout intervals. We take advantage of this structure by categorizing bouts into discrete types and representing their behavior as labeled sequences of bout-types emitted over time. We then construct probabilistic models – specifically, marked renewal processes – to evaluate how bout-types and interbout intervals are selected by the fish as a function of its internal hunger state, behavioral history, and the locations and properties of nearby prey. Finally, we evaluate the models by their predictive likelihood and their ability to generate realistic trajectories of virtual fish swimming through simulated environments. Our simulations capture multiple timescales of structure in larval zebrafish behavior and expose many ways in which hunger state influences their action selection to promote food seeking during hunger and safety during satiety. -
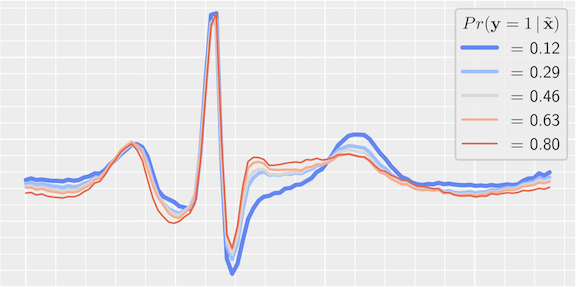
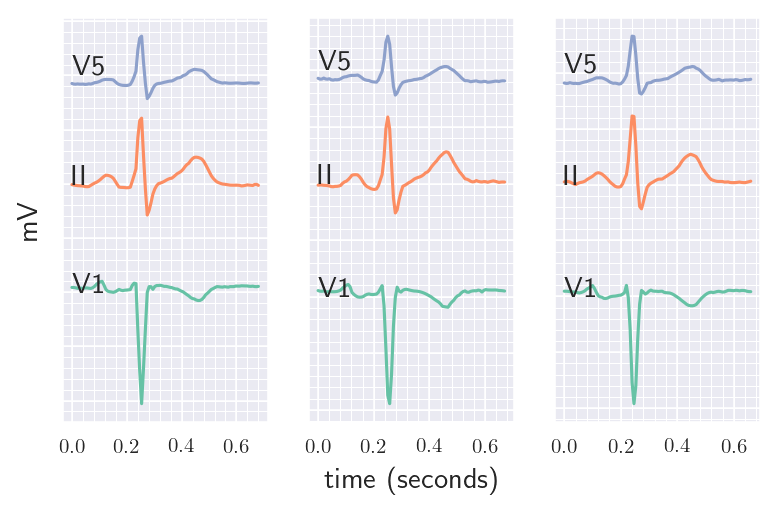
Discriminative Regularization for Latent Variable Models with Applications to Electrocardiography
Andrew C. Miller, Ziad Obermeyer, John P. Cunningham, and Sendhil Mullainathan
International Conference on Machine Learning (ICML), 2019
[abstract] [pdf]Generative models often use latent variables to represent structured variation in high-dimensional data, such as images and medical waveforms. However, these latent variables may ignore subtle, yet meaningful features in the data. Some features may predict an outcome of interest (e.g. heart attack) but account for only a small fraction of variation in the data. We propose a generative model training objective that uses a black-box discriminative model as a regularizer to learn representations that preserve this predictive variation. With these discriminatively regularized latent variable models, we visualize and measure variation in the data that influence a black-box predictive model, enabling an expert to better understand each prediction. With this technique, we study models that use electrocardiograms to predict outcomes of clinical interest. We measure our approach on synthetic and real data with statistical summaries and an experiment carried out by a physician. -
A Comparison of Patient History- and EKG-based Cardiac Risk Scores
Andrew C. Miller, Ziad Obermeyer, and Sendhil Mullainathan
Proceedings of the AMIA Summit on Clinical Research Informatics (CRI), 2019
[abstract] [pdf]Patient-specific risk scores can be used to identify individuals at elevated risk for cardiovascular disease. Typically, risk scores are based on patient habits and history — age, sex, race, smoking behavior, and prior vital signs and diagnoses. We explore an alternative source of information, a patient's raw electrocardiogram recording, and develop a score of patient risk of certain outcomes. We compare models that predict disease onset following an emergency department visit, including stroke, atrial fibrillation, and other adverse cardiac events. We show that a learned representation (e.g.~deep neural network) of raw EKG waveforms can improve prediction of cardiac abnormalities over traditional risk factors. Further, we show that a simple predictor based on segmented heart beats performs as well or better than a complex convolutional network recently shown to reliably automate arrhythmia detection in EKG observations. We analyze a large cohort of emergency department patients and show evidence that EKG-derived risk scores can be more robust to patient heterogeneity. -
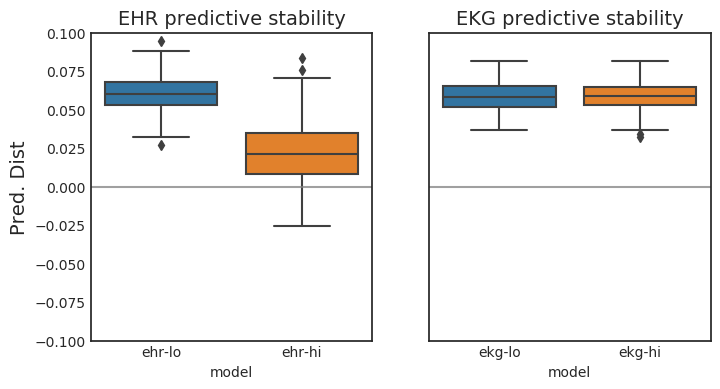
Measuring the Stability of EHR- and EKG-based Predictive Models
Andrew C. Miller, Ziad Obermeyer, and Sendhil Mullainathan
Machine Learning for Health (NeurIPS Workshop), 2018
[abstract] [arxiv]Databases of electronic health records (EHRs) are increasingly used to inform clinical decisions. Machine learning algorithms can find patterns in EHRs that are predictive of future adverse outcomes. However, statistical models may be built upon patterns of health-seeking behavior that vary across patient subpopulations, leading to poor predictive performance when training on one patient population and predicting on another. This note proposes two tests to better measure and understand model generalization. We use these tests to compare models derived from two data sources: (i) historical medical records, and (ii) electrocardiogram (EKG) waveforms. In a predictive task, we show that EKG-based models can be more stable than EHR-based models across different patient populations. -
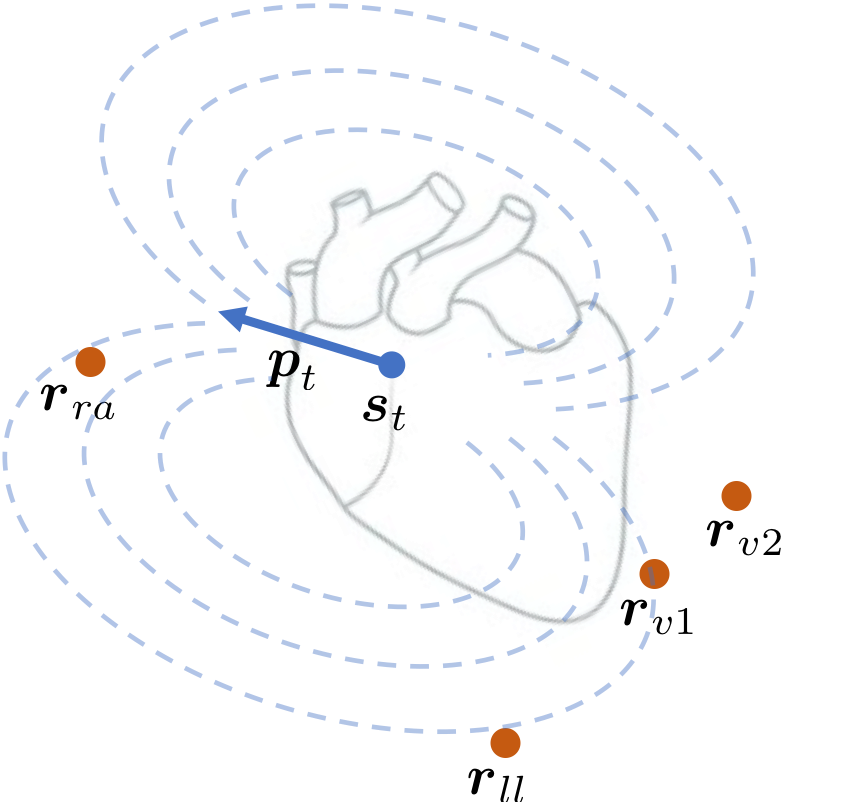
A Probabilistic Model of Cardiac Physiology and Electrocardiograms
Andrew C. Miller, Ziad Obermeyer, David M. Blei, John P. Cunningham, and Sendhil Mullainathan
Machine Learning for Health (NeurIPS Workshop), 2018
[abstract] [arxiv]An electrocardiogram (EKG) is a common, non-invasive test that measures the electrical activity of a patient's heart. EKGs contain useful diagnostic information about patient health that may not be found other electronic health record (EHR) data. As multi-dimensional waveforms, they could be modeled using generic machine learning tools, such as a linear factor model or a variational autoencoder. We take a different approach: we specify a model that directly represents the underlying electrophysiology of the heart and the EKG measurement process. The resulting generative model can solve a variety of downstream tasks that standard supervised or unsupervised learning approaches cannot handle. We apply our model to two datasets, including a sample of emergency department patients with traditional EKG reports that have a lot of missing data. We show that our model can more accurately reconstruct missing data (measured by test reconstruction error) than a standard baseline when there is significant missing data. More broadly, this physiological representation creates features of heart function that may be useful in a variety of settings, including prediction, causal analysis, and discovery. -
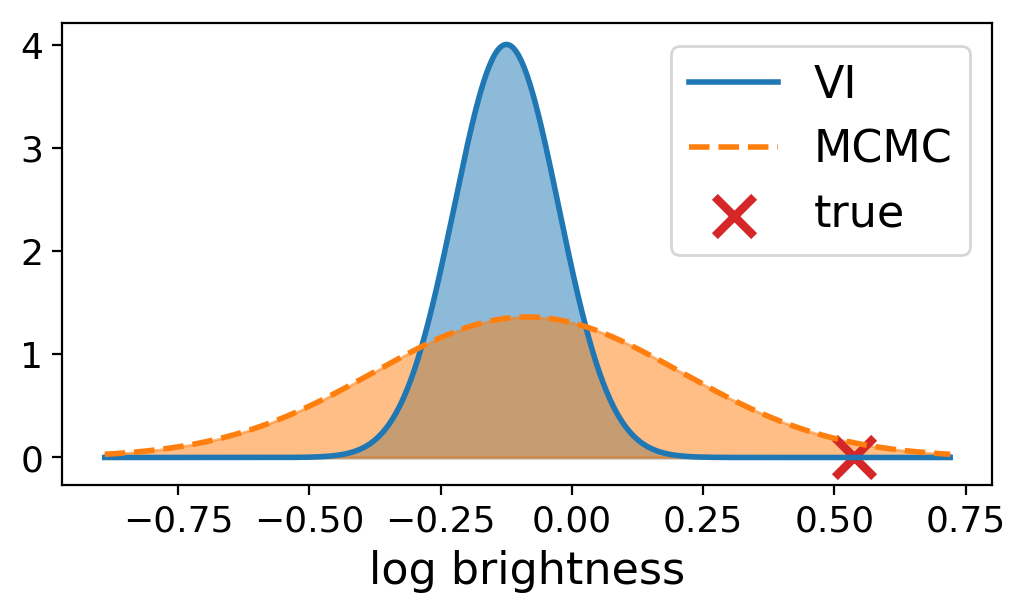
Approximate Inference for Constructing Astronomical Catalogs from Images
Jeffrey Regier, Andrew C. Miller, David Schlegel, Ryan P. Adams, Jon D. McAuliffe, and Prabhat
Annals of Applied Statistics (in press), 2019
[abstract] [arxiv]We present a new, fully generative model for constructing astronomical catalogs from optical telescope image sets. Each pixel intensity is treated as a Poisson random variable with a rate parameter that depends on the latent properties of stars and galaxies. These latent properties are themselves random, with scientific prior distributions constructed from large ancillary datasets. We compare two procedures for posterior inference: Markov chain Monte Carlo (MCMC) and variational inference (VI). MCMC excels at quantifying uncertainty while VI is 1000× faster. Both procedures outperform the current state-of-the-art method for measuring celestial bodies’ colors, shapes, and morphologies. On a supercomputer, the VI procedure efficiently uses 665,000 CPU cores (1.3 million hardware threads) to construct an astronomical catalog from 50 terabytes of images. -
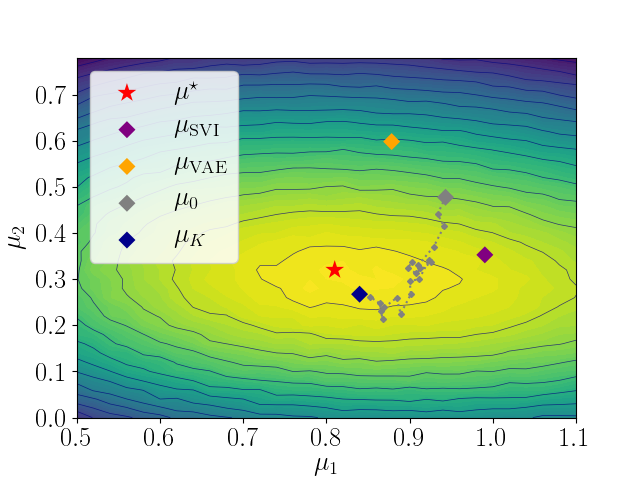
Semi-Amortized Variational Autoencoders
Yoon Kim, Sam Wiseman, Andrew C. Miller, David Sontag, Alexander M. Rush
International Conference on Machine Learning (ICML), 2018
[abstract] [arxiv]Amortized variational inference (AVI) replaces instance-specific local inference with a global inference network. While AVI has enabled efficient training of deep generative models such as variational autoencoders (VAE), recent empirical work suggests that inference networks can produce suboptimal variational parameters. We propose a hybrid approach, to use AVI to initialize the variational parameters and run stochastic variational inference (SVI) to refine them. Crucially, the local SVI procedure is itself differentiable, so the inference network and generative model can be trained end-to-end with gradient-based optimization. This semi-amortized approach enables the use of rich generative models without experiencing the posterior-collapse phenomenon common in training VAEs for problems like text generation. Experiments show this approach outperforms strong autoregressive and variational baselines on standard text and image datasets. -
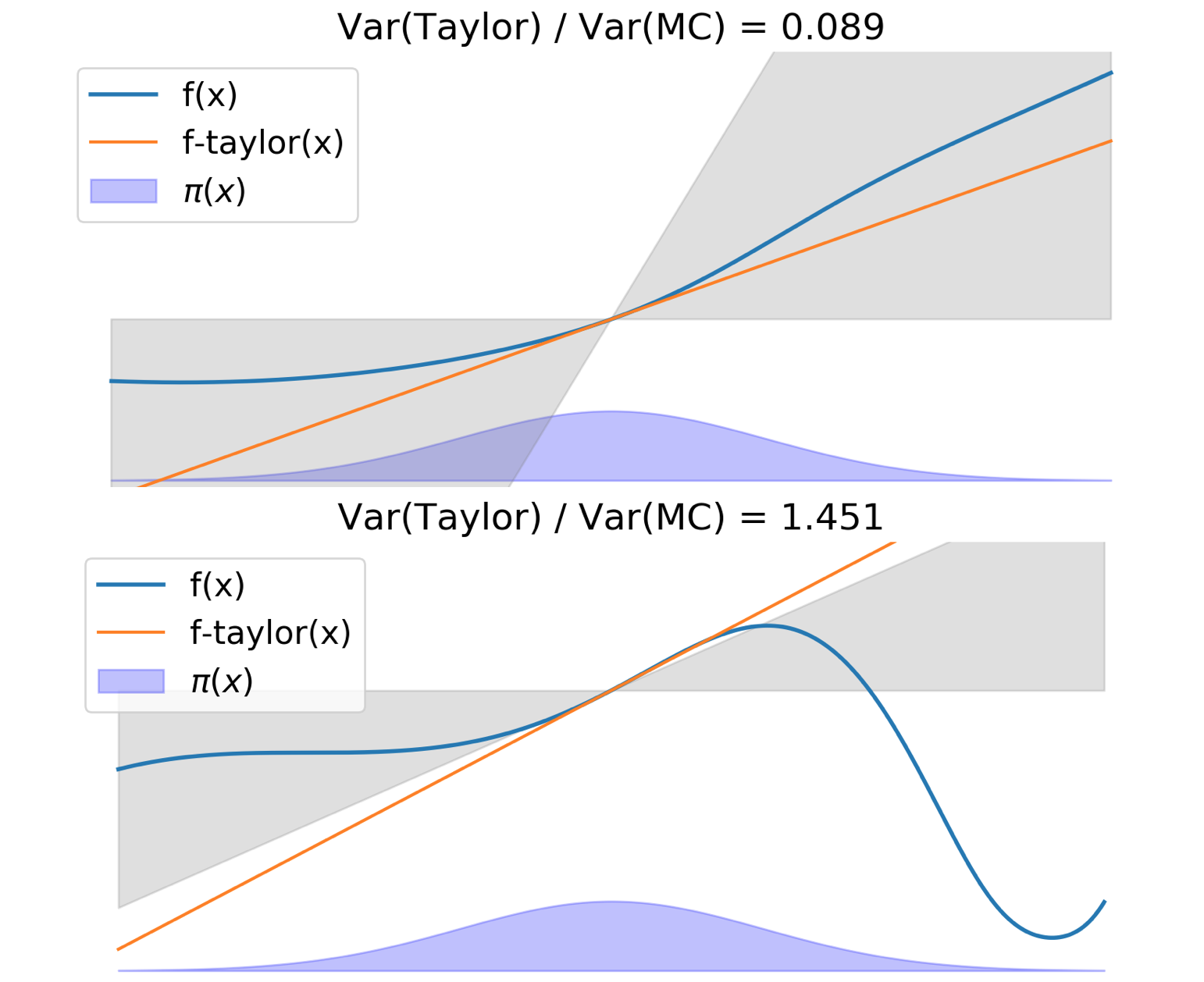
Taylor Residual Estimators via Automatic Differentiation
Andrew C. Miller, Nicholas J. Foti, Ryan P. Adams
Advances in Approximate Bayesian Inference (NeurIPS Workshop), 2017
[abstract] [pdf]We develop a method for reducing the variance of Monte Carlo estimators against distributions with known moments, termed Taylor residual Monte Carlo estimators (TREs). We analyze the variance of TREs, and derive conditions under which TREs outperform the original Monte Carlo estimators in terms of estimator variance. Additionally, modern automatic differentiation tools can be leveraged to efficiently compute these new estimators. The utility of TREs is demonstrated on a Monte Carlo variational inference problem. -
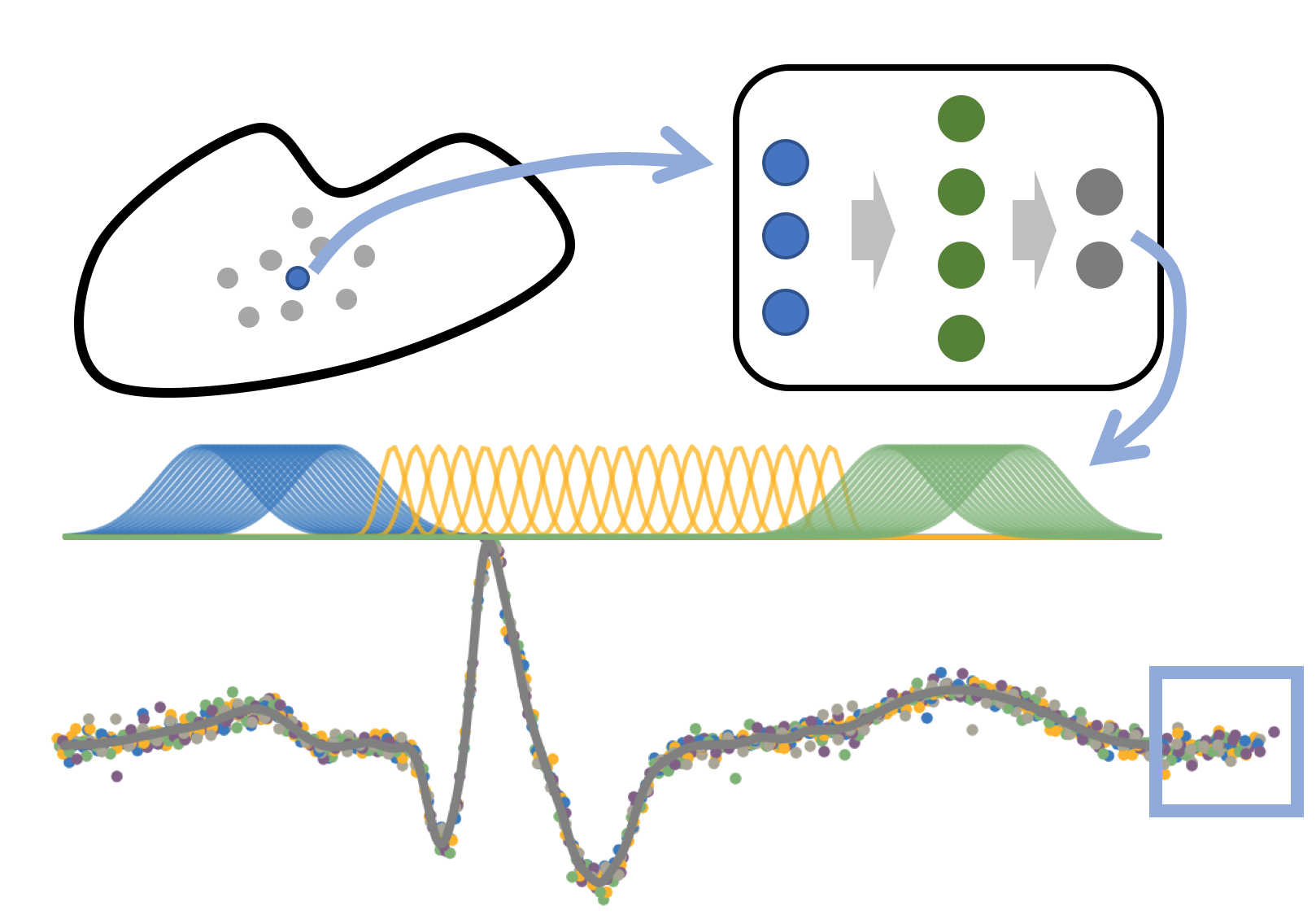
A Hierarchical Generative Model of Electrocardiogram Records
Andrew C. Miller, Sendhil Mullainathan, Ziad Obermeyer
Machine Learning for Health (NeurIPS Workshop), 2017
[abstract] [pdf]We develop a probabilistic generative model of electrocardiogram (EKG) tracings. Our model describes multiple sources of variation in EKGs, including patient- specific cardiac cycle morphology and between-cycle variation that leads to quasi- periodicity. We use a deep generative network as a flexible model component to describe variation in beat-specific morphology. We apply our model to a set of 549 EKG records, including over 4,600 unique beats, and show that it is able to discover interpretable information, such as patient similarity and meaningful physiological features (e.g., T wave inversion). -
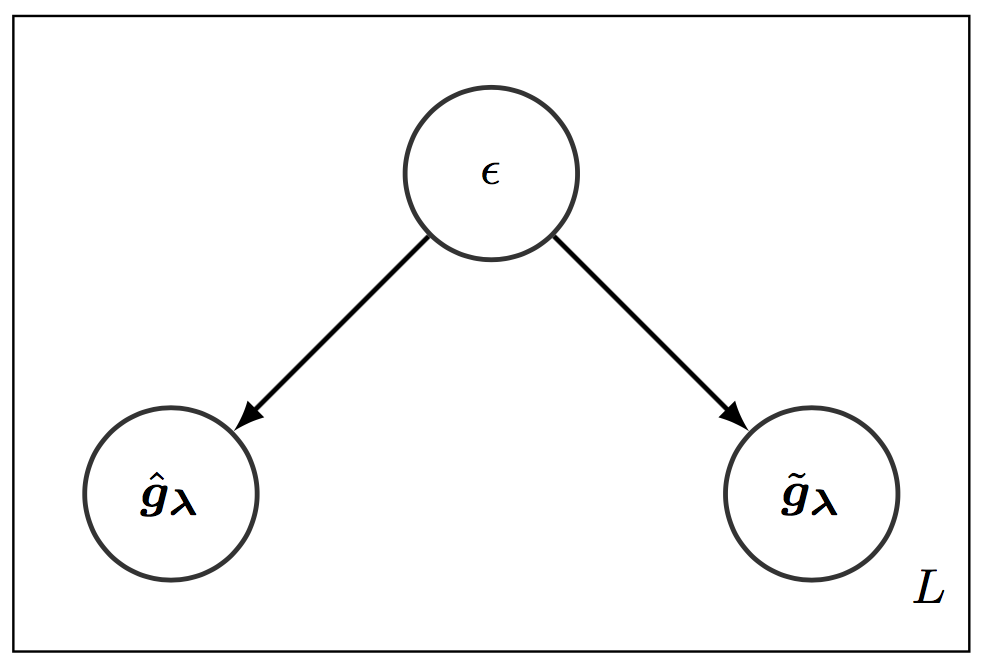
Reducing Reparameterization Gradient Variance
Andrew C. Miller, Nicholas J. Foti, Alexander D'Amour, and Ryan P. Adams
Advances in Neural Information Processing Systems (NeurIPS), 2017
[abstract] [arxiv] [code]Optimization with noisy gradients has become ubiquitous in statistics and machine learning. Reparameterization gradients, or gradient estimates computed via the “reparameterization trick,” represent a class of noisy gradients often used in Monte Carlo variational inference (MCVI). However, when these gradient estimators are too noisy, the optimization procedure can be slow or fail to converge. One way to reduce noise is to use more samples for the gradient estimate, but this can be computationally expensive. Instead, we view the noisy gradient as a random variable, and form an inexpensive approximation of the generating procedure for the gradient sample. This approximation has high correlation with the noisy gradient by construction, making it a useful control variate for variance reduction. We demonstrate our approach on non-conjugate multi-level hierarchical models and a Bayesian neural net where we observed gradient variance reductions of multiple orders of magnitude (20-2,000x). -
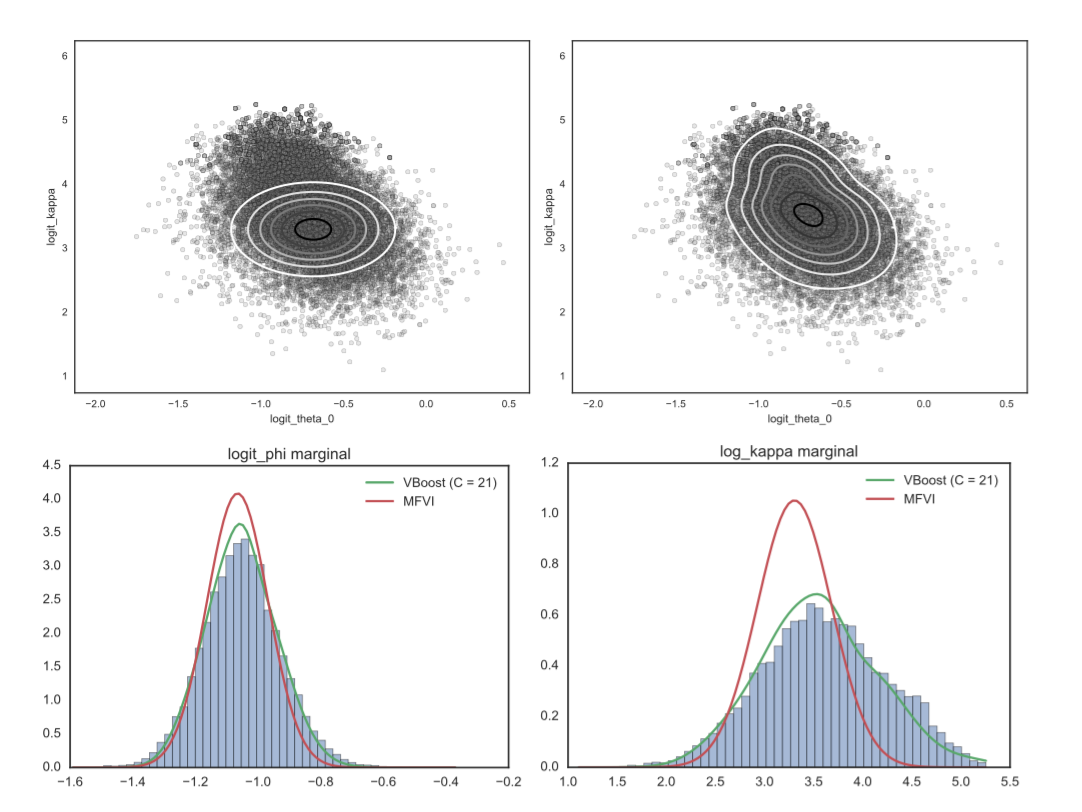
Variational Boosting: Iteratively Refining Posterior Approximations
Andrew C. Miller, Nicholas J. Foti, and Ryan P. Adams
International Conference on Machine Learning (ICML), 2017
Early version in AABI 2016 (NeurIPS Workshop)
[abstract] [arxiv] [code]Abstract: We present a black-box variational inference (BBVI) method to approximate intractable posterior distributions with an increasingly rich approximating class. Using mixture distributions as the approximating class, we first describe how to apply the re-parameterization trick and existing BBVI methods to mixtures. We then describe a method, termed Variational Boosting, that iteratively refines an existing approximation by defining and solving a sequence of optimization problems, allowing the practitioner to trade computation time for increased accuracy. -
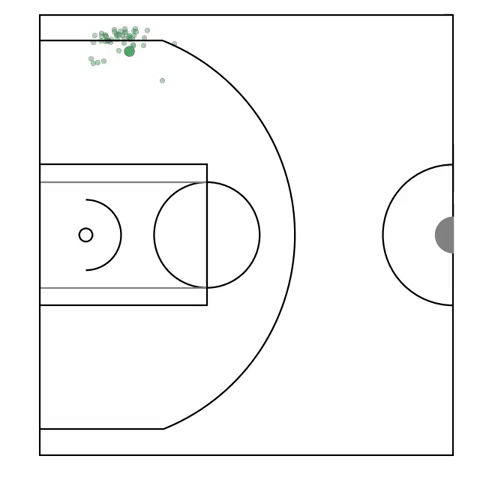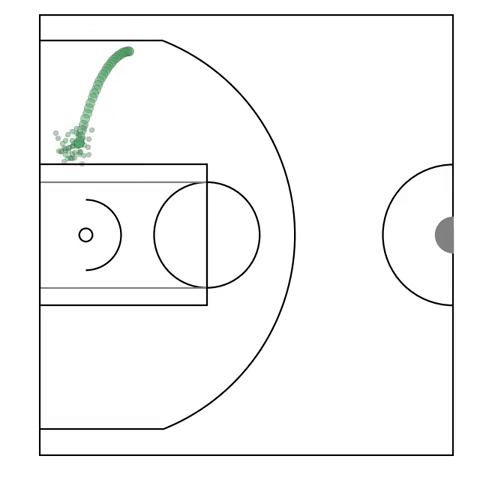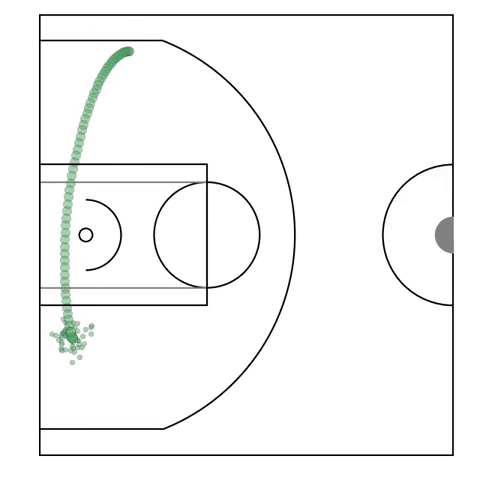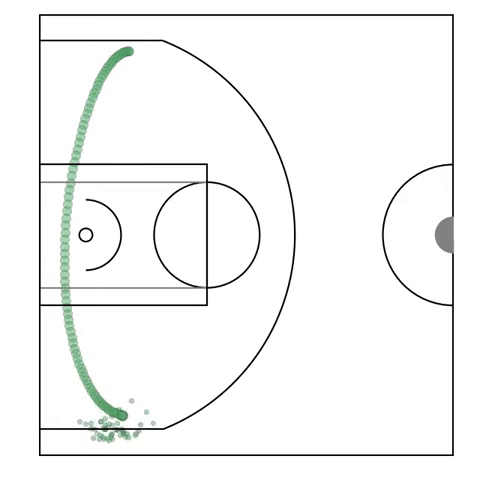
Possession Sketches: Mapping NBA Strategies
Andrew C. Miller and Luke Bornn
MIT Sloan Sports Analytics Conference, 2017
third place, MIT SSAC Research Paper Competition
[abstract] [pdf]We develop a method for automatically organizing and exploring possessions of basketball player-tracks by offensive structure. Our method centers around building a data-driven dictionary of individual player actions, and then fitting a global hierarchical model to all possessions, yielding a concise summary, or sketch of the collective action taken by the offensive team in a basketball possession. -
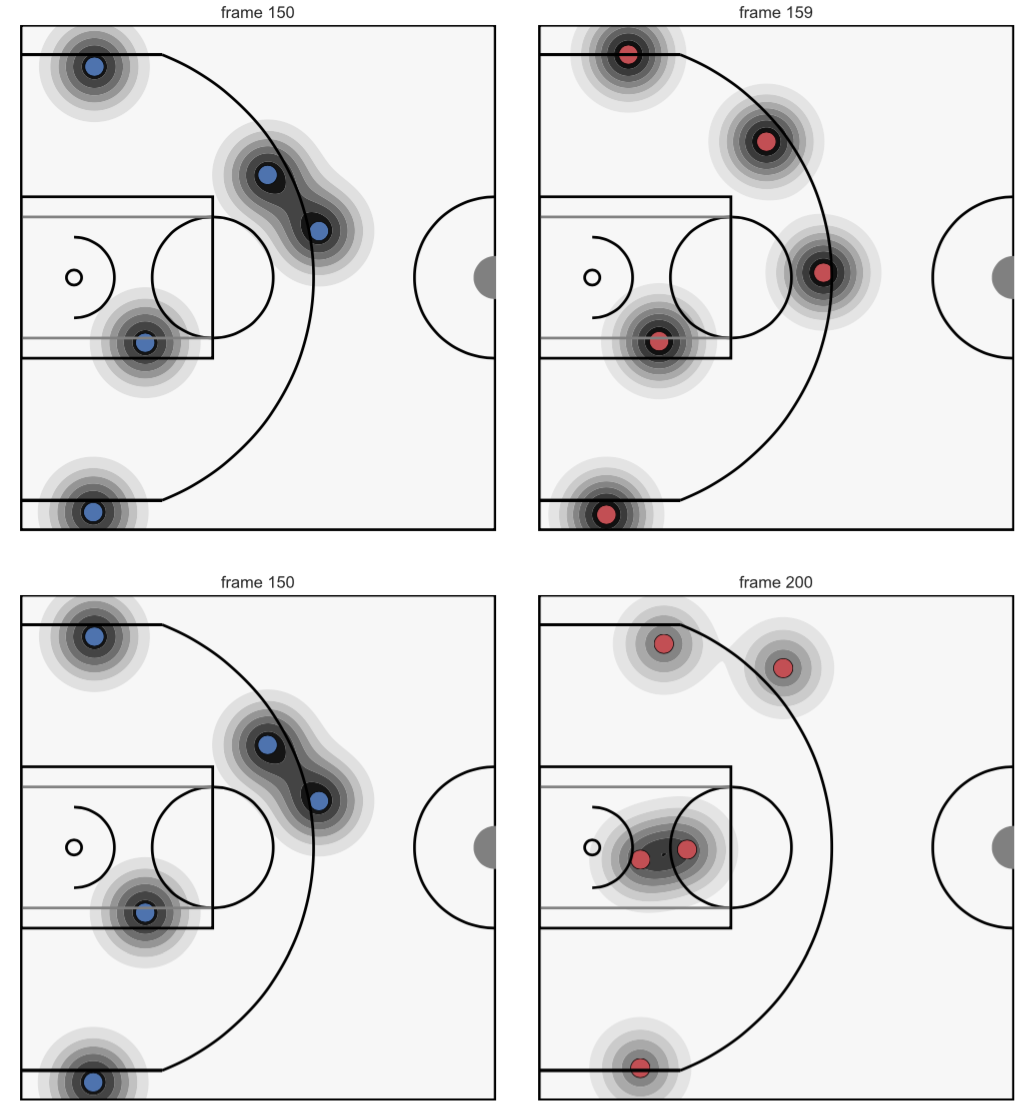
Learning a Similarity Measure for Dynamic Point Clouds
Andrew C. Miller and Luke Bornn
in submission
[abstract]Abstract: We develop a novel measure of similarity between two dynamic point clouds, where a dynamic point cloud is a collection of spatiotemporal trajectories representing multiple agents moving and interacting. Certain types of variation in trajectory data make this challenging; two dynamic point clouds may describe the same joint action, but sub-actions may occur at different speeds, spatial locations, or may be performed by different agents. As such, for the purposes of clustering and classification, known similarity measures fail. To solve this problem we construct a similarity measure in two parts. We first construct a novel distance metric between two sets of points (i.e. static point clouds). We then integrate this distance metric into dynamic time warping, yielding a similarity measure between dynamic point clouds. The resulting similarity measure is invariant to permutation of the agents and robust to spatiotemporal variation. Importantly, we describe how to differentiate through dynamic time warping in order to learn a similarity measure specific to an objective function. We use our method to describe the similarity of basketball sequences using player-tracking data from the National Basketball Association. -
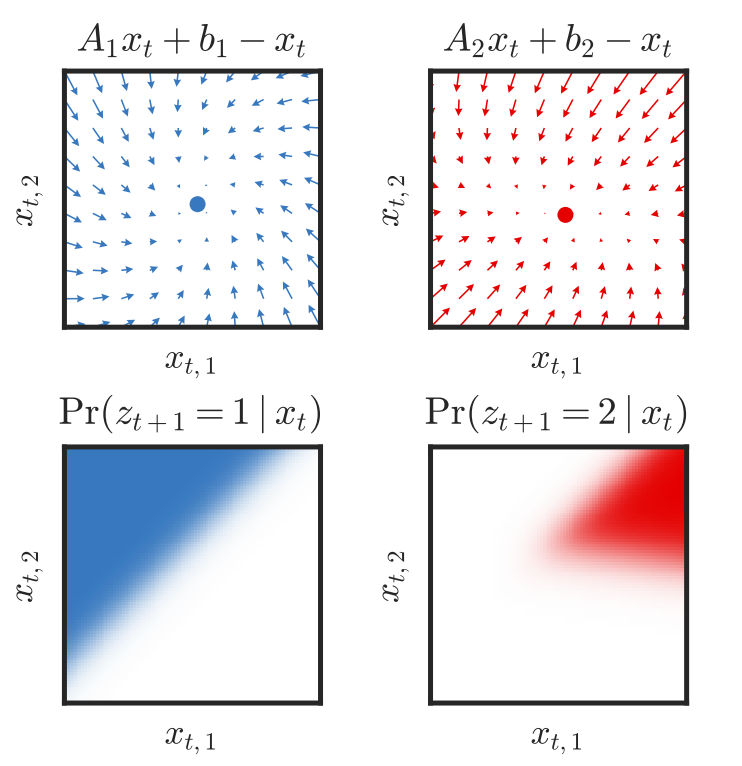
Bayesian Learning and Inference in Recurrent Switching Linear Dynamical Systems
Scott W. Linderman, Matthew J. Johnson, Andrew C. Miller, Ryan P. Adams, David M. Blei, and Liam Paninski
AISTATS, 2017
[abstract] [arxiv] [aistats]Abstract: Many natural systems, such as neurons firing in the brain or basketball teams traversing a court, give rise to time series data with complex, nonlinear dynamics. We can gain insight into these systems by decomposing the data into segments that are each explained by simpler dynamic units. Building on switching linear dynamical systems (SLDS), we present a new model class that not only discovers these dynamical units, but also explains how their switching behavior depends on observations or continuous latent states. These "recurrent" switching linear dynamical systems provide further insight by discovering the conditions under which each unit is deployed, something that traditional SLDS models fail to do. We leverage recent algorithmic advances in approximate inference to make Bayesian inference in these models easy, fast, and scalable. -
A Gaussian Process Model of Quasar Spectral Energy Distributions
Andrew C. Miller, Albert Wu, Jeffrey Regier, Jon McAuliffe, Dustin Lang, Mr Prabhat, David Schlegel, and Ryan P. Adams
Advances in Neural Information Processing Systems (NeurIPS), 2015
[abstract] [pdf]Abstract: We propose a method for combining two sources of astronomical data, spectroscopy and photometry, which carry information about sources of light (e.g., stars, galaxies, and quasars) at extremely different spectral resolutions. Our model treats the spectral energy distribution (SED) of the radiation from a source as a latent variable, hierarchically generating both photometric and spectroscopic observations. We place a flexible, nonparametric prior over the SED of a light source that admits a physically interpretable decomposition, and allows us to tractably perform inference. We use our model to predict the distribution of the redshift of a quasar from five-band (low spectral resolution) photometric data, the so called "photo-z" problem. Our method shows that tools from machine learning and Bayesian statistics allow us to leverage multiple resolutions of information to make accurate predictions with well-characterized uncertainties. -
Advances in nowcasting influenza-like illness rates using search query logs
Vasileios Lampos, Andrew C. Miller, Steve Crossan, and Christian Stefansen
Scientific Reports, 2015
[abstract] [pdf]Description: This paper presents an improvement on the Google Flu Trends model, an epidemiological surveillance tool for measuring the current rate of influenza like illness (ILI) in the population. These methods relate patterns in user search queries to historical influenza estimates to obtain real-time ILI estimates. We develop a non-linear model based on Gaussian processes and a family of autoregressive models. We compare it to many already proposed methods, assessing predictive performance over five years of flu seasons, 2008-2013, and show that it obtains state of the art predictive performance. -

Celeste: Variational inference for a generative model of astronomical images
Jeffrey Regier, Andrew C. Miller, Jon McAuliffe, Ryan Adams, Matt Hoffman, Dustin Lang, David Schlegel, and Mr Prabhat
International Conference on Machine Learning (ICML), 2015
[abstract] [icml]We present a new, fully generative model of optical telescope image sets, along with a variational procedure for inference. Each pixel intensity is treated as a Poisson random variable, with a rate parameter dependent on latent properties of stars and galaxies. Key latent properties are themselves random, with scientific prior distributions constructed from large ancillary data sets. We check our approach on synthetic images. We also run it on images from a major sky survey, where it exceeds the performance of the current state-of-the-art method for locating celestial bodies and measuring their colors. -
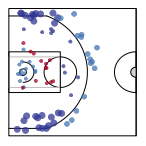
Characterizing the Spatial Structure of Defensive Skill in Professional Basketball
Alexander Franks, Andrew Miller, Luke Bornn, and Kirk Goldsberry
The Annals of Applied Statistics, 2015
[abstract] [AoAS] [arxiv]Description: We develop a spatial model to analyze the defensive ability of professional basketball players. We first define two preprocessing steps to find a representation of players and posessions, and then we define a parametric model with effects that correspond to interpretable defensive ability. -
Counterpoints: Advanced Defensive Metrics for NBA Basketball
Alexander Franks*, Andrew Miller*, Luke Bornn, and Kirk Goldsberry
MIT Sloan Sports Analytics Conference, 2015
best paper award, MIT SSAC Research Paper Competition
[more] [pdf] [talk]press: Description: This paper develops new advanced defensive metrics for measuring the ability of professional basketball players, derived from player tracking data. We use a who's guarding whom model to define a new suite of metrics designed to measure how suppressive and disruptive players are on average, and throughout the entire possession. -
Factorized Point Process Intensities: A Spatial Analysis of Professional Basketball
Andrew Miller, Luke Bornn, Ryan Adams and Kirk Goldsberry
International Conference on Machine Learning (ICML), 2014
[more] [arxiv]Description: We develop a dimensionality reduction method that can be applied to collections of point processes on a common space. Using this representation, we analyze the shooting habits of professional basketball players, create a new characterization of offensive player types and model shooting efficiency. -

A Heterogeneous Framework for Large-Scale Dense 3-d Reconstruction from Aerial Imagery
Andrew Miller, Vishal Jain and Joseph L. Mundy
[more]This paper presents a scalable system of multiple GPUs and CPUs to reconstruct dense 3-D models. This is a continuation Miller 2011 (which constructed models of size ~ 1 billion voxels) that extends the system to models in the 50-100 billion voxel range. Results are shown for building a 3-d model of an area of about 2 square kilometers (< 1 meter resolution) represented by 50 billion voxels over 4 GPUs in near real-time.
Demo rendering:
-

A Multi-sensor Fusion Framework in 3-D
Vishal Jain, Andrew Miller and Joseph L. Mundy
2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
[more] [pdf]This paper presents a system that fuses both optical and infrared imagery to build a volumetric model. We develop a technique to tightly register multiple volumetric models, and show the benefits of the multi-modal datasource by developing classifiers to label high level features of the landscape (road, sidewalk, pavement, buildings, etc.). -
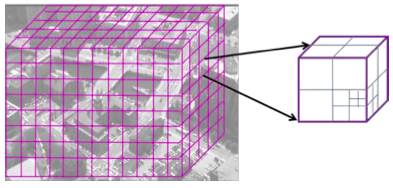
Real-time rendering and dynamic updating of 3-d volumetric data
Andrew Miller, Vishal Jain and Joseph L. Mundy
Proceedings of the Fourth Workshop on General Purpose Processing on Graphics Processing Units, ASPLOS 2011
[more] [pdf]We develop and optimize a parallel ray tracing-inspired algorithm for both constructing and rendering a high fidelity 3-d volumetric model from aerial imagery. This paper goes over the engineering effort to gain an 800x speedup over serial implementations using a single gpu.
Recent Talks
- A Comparison of Patient History- and EKG-based Cardiac Risk Scores, AMIA Informatics Summit (Mar 2018)
- Statistics, Machine Learning, and Computational Medicine, UCSB (Feb 2018)
- Invited Speaker, Department of Computer Science, Rice University (Feb 2018)
- Invited Speaker, Computer Science Department, UCLA (Feb 2018)
- Taylor Residual Estimators via Automatic Differentiation. Advances in Approximate Bayesian Inference, NeurIPS Workshop (Dec 2017)
- Advances in Monte Carlo Variational Inference. CS Colloquium, Viterbi School of Engineering, USC. (Nov 2017)
- Possession Sketches: Mapping NBA Strategies. MIT Sloan Sports Analytics Conference. (Mar 2017)
- Stealing the Playbook: Structure discovery in NBA player-tracking data. The Cascadia Symposium on Statistics in Sports. (Sept 2016)
- Communication Panel, NFL Football Performance and Technology Symposium, Indianapolis, IN. (Feb 2016)
- Counterpoints: Advanced Defensive Metrics for NBA Basketball. MIT Sloan Sports Analytics Conference. (Feb 2015)
- Characterizing the Spatial Structure of Defensive Skill in Professional Basketball. KDD Workshop on Large-Scale Sports Analytics. (Aug 2014)
- A Spatiotemporal Analysis of Professional Basketball. Joint Statistical Meetings, 2014. Session: Bayes and Big Data. (Aug 2014)
- Factorized Point Process Intensities: A Spatial Analysis of Professional Basketball. International Conference on Machine Learning, Beijing, China. (June 2014)
- Quantifying Offensive Player Types in the NBA with Non-Negative Matrix Factorization. New England Symposium on Statistics in Sports, Harvard University, Cambridge, MA. (Sept 2013)